Named Entity Recognition Dataset
Build AI systems that accurately identify names, locations, dates, and more with high-quality annotated datasets

Introduction
Named Entity Recognition (NER) is a cornerstone of natural language processing (NLP), enabling AI systems to classify and extract meaningful entities from text. Our NER Dataset is curated with precision to support applications like document analysis, chatbots, and information retrieval systems. Designed for accuracy and diversity, this dataset is the ideal choice for training your AI to understand and process real-world text.

Discover How This Dataset Can:
- Enhance Text Analysis: Train models to extract entities such as names, organizations, and dates from unstructured text with high precision
- Improve Chatbot Interactions: Develop AI systems that can identify and respond to entity-specific queries, enhancing user experiences.
- Support Document Automation: Enable AI tools to automatically process and categorize entities within large volumes of text.
- Boost Information Retrieval: Build systems that can efficiently locate and extract relevant entities from diverse datasets.
Use Cases
This dataset is ideal for:
Document Processing AI
Automate entity recognition in legal documents, invoices, and contracts to streamline workflows.
Customer Service Chatbots
Train chatbots to identify and handle queries involving names, locations, or product details with improved accuracy.
Content Categorization
Develop systems to tag and categorize text content for better organization and searchability.
Search Engine Optimization
Enhance search engines with entity-based indexing and ranking for improved query relevance.
Why Choose Sapien's Dataset?
Why Choose Sapien for Named Entity Recognition?
Diverse and Comprehensive Data
Our datasets include a variety of text types, from legal and financial documents to social media posts, covering a wide range of entity categories.
Detailed Annotations
Every dataset is meticulously labeled with entities such as names, locations, dates, and organizations to ensure accuracy and usability.
Multilingual Coverage
Train your AI to recognize entities in multiple languages, enabling global applications and cross-lingual understanding.
Customizable Solutions
We offer tailored datasets to match your specific project requirements, whether you're focusing on a niche industry or scaling for broader applications.
Privacy and Compliance
All data is collected and processed in adherence to strict privacy and regulatory guidelines, ensuring ethical use.
Case Studies

Accurate Data Labeling for Voice Security: Reality Defender's Success Story


테일러링 프리시젼: 소셜 미디어 콘텐츠 분석 프로젝트
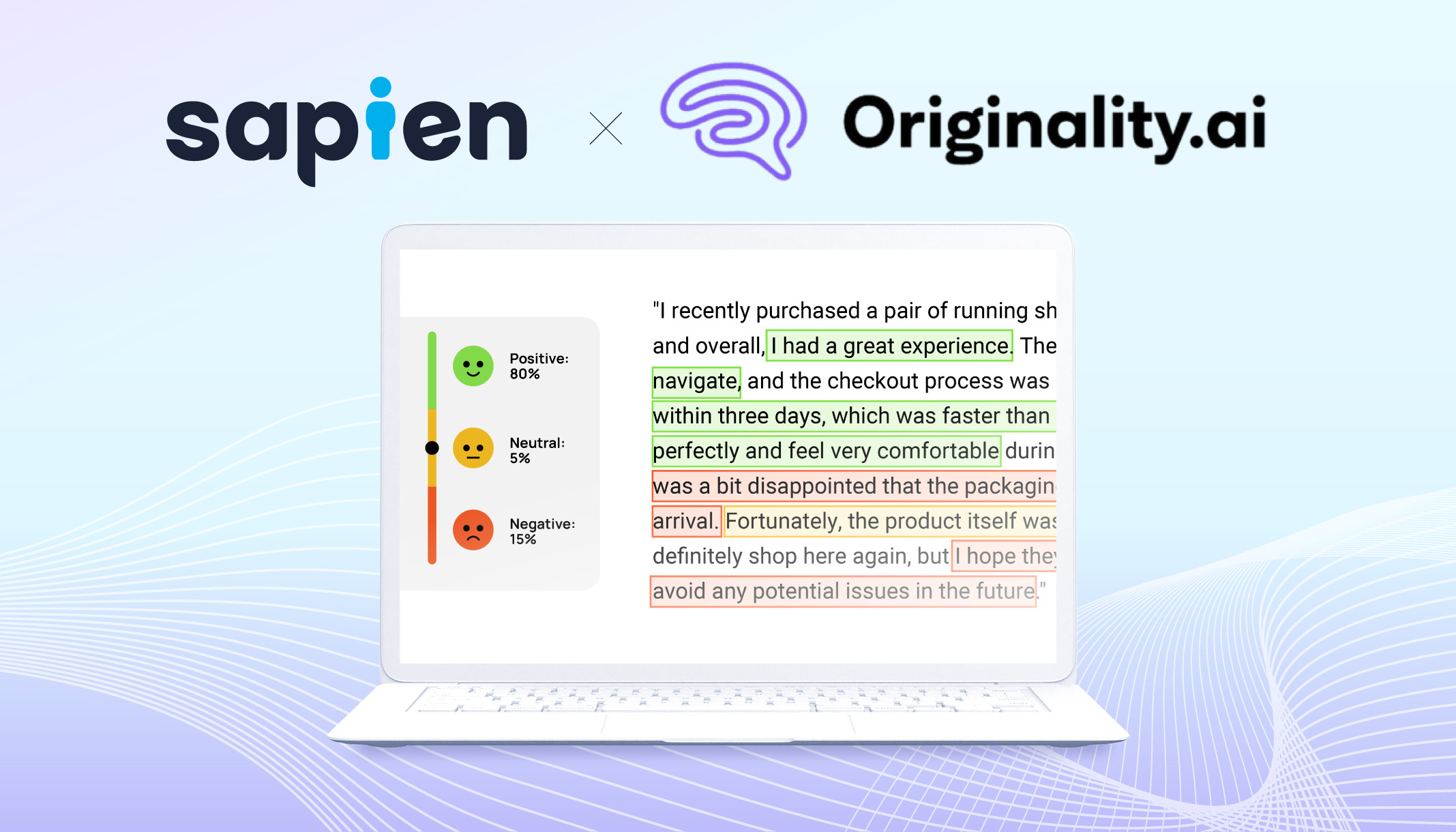
진정성 구현: Sapien의 텍스트 주석 전문 지식으로 Originality.ai 개선

Ready to Build Smarter AI with NER Data?
Access high-quality datasets to train your AI for accurate and efficient named entity recognition
Let's Talk
Have a specific dataset need or a question? Contact us today, and we’ll help you find the perfect solution.